 Почему варочная панель слабо греет: 7 причин от неправильной посуды до поломки ТЭНа
Почему варочная панель слабо греет: 7 причин от неправильной посуды до поломки ТЭНа ...
Будущее программирования
 thedeemon — 20.04.2011
В будущем программирования не будет.
thedeemon — 20.04.2011
В будущем программирования не будет.Знаете, 200 лет назад была такая профессия - фонарщик: надо было ходить по вечерам зажигать уличные фонари, а утром их тушить. И сайт ХэдъХантырь.ру пестрел объявлениями "Компании Люксофтъ требуются junior и senior фонарщики, умеющие обращаться с керосином и газом, наличие своей лестницы приветствуется, карьерный рост и соцпакет гарантируется". Фонарей становилось все больше, рынок рос, спрос на фонарщиков тоже. Но потом их работа была автоматизирована, фонарщиков не стало. Хотя это не значит, что ИТ-индустрия ("иллюминацонных технологий") пропала, она просто преобразилась, с тех пор выросши на порядки.
Как работает любая программа? У нее есть некий набор событий, которые она умеет воспринимать (действия пользователя, запросы от системы или других программ, в том числе по сети) и в ответ на эти события она что-то меняет в мире (что-то становится нарисовано на экране, что-то послано по сети в ответ, что-то записано на диске). Если у нас будет язык, на котором можно формально описать:
а) входные данные и состояние системы, причем не только их формат, но и свойства и взаимосвязи,
б) результат - желаемое состояние системы, и
в) нефункциональные требования (например, приоритет скорости над потреблением памяти или наоборот),
то все остальное компьютер сможет делать сам - найти оптимальный способ трансформации состояния из исходного в нужное, т.е. сам построить алгоритм, программу - то, что сегодня делают программисты. Для этого нужно лишь иметь набор примитивных функций, для которых так же подробно описаны их входы и выходы, и подобно тому, как сегодня работает вывод типов в ряде языков, сделать вывод свойств - оценку сложности и потребления памяти и других ресурсов. Фактически, задача построения алгоритма сведется к поиску оптимального пути в графе, где вершины - состояния, дуги - функции, а веса дуг - характеристики функций, вроде потребления определенных ресурсов. Сегодня задача поиска пути из Массачусетса в Аризону через сотни тысяч дорог, дорожек и населенных пунктов решается за долю секунды. В графе с намного более типизированными вершинами это можно делать еще быстрее.
Между прочим, рабочий прототип такой системы есть уже сегодня у каждого пользователя Windows - это движок DirectShow, используемый медиаплеерами и некоторыми другими приложениями. DirectShow оперирует графами, где потоки типизированных данных перемещаются между черными ящиками, преобразующими из из одного типа в другой. Например, мы хотим вывести на экран видео из некоего файла. Берем читалку файлов (фильтр File source) и видеоокошко (фильтр Video Renderer):
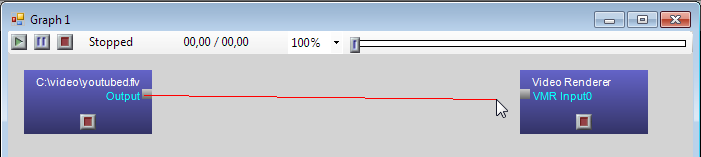
и просим движок DirectShow их соединить. Окошко не знакомо с форматами файлов и способами сжатия видео, оно умеет принимать на вход данные нескольких видов несжатых картинок. Читалка файлов тоже ничего не знает про форматы и сжатие, она просто читает файлы. Что делает движок DirectShow? У него есть база фильтров, про которые известно, какие форматы они умеют принимать на вход и выдавать на выход. Фактически, это функции. Например, декодер XviD есть функция из MPEG4 в Uncompressed_Video. Нередко выходной тип данных зависит от значений, полученных на входе, например AVI Splitter на входе имеет AVI файл, а на выходе в зависимости от содержимого файла может быть MPEG4, MJPEG, Huffyuv и еще сотни форматов. Зависимые типы, ага. И вот, пользуясь этой базой, а также при необходимости инстанцируя и "примеряя" некоторые фильтры, движок ищет последовательность фильтров, которая бы имела нужный вход и нужный выход, т.е. композицию функций нужного типа. По сути это задача поиска пути в графе, где типы данных - вершины, а фильтры-функции - дуги. Найдя путь, движок вставляет нужные фильтры и соединяет их в цепочку:
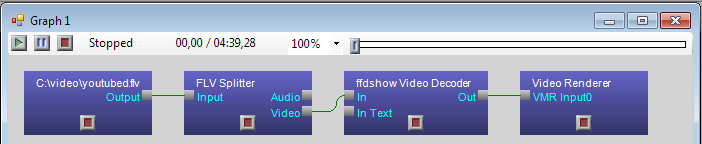
Фактически, компьютер только что придумал алгоритм: что делать, чтобы вывести видео из данного файла, какие операции над данными и в какой последовательности предпринимать. В данном случае искомая функция типа File -> Uncompressed_Video получается композицией функций FLV Splitter типа File -> Video_FLV1 и ffdshow decoder типа Video_FLV1 -> Uncompressed_Video. На картинке граф другого вида: в конкретных графах DirectShow наоборот вершины - фильтры, а дуги - данные, но это представление изоморфно вышеописанному.
Ту же схему можно применить и для построения произвольных программ, просто типы должны более детально описывать данные и состояния, а библиотека фильтров-функций должна быть достаточно хорошей. Скорее всего, примитивных функций нужно не так уж много, базового набора из Кнута/Кормена/Окасаки/whatever должно хватить для большинства задач. Понятно, что в большинстве случаев подходящих путей в таком графе будет очень много (proof irrelevance). В DirectShow в случае множественности возможных путей выбор происходит на основе приоритетов фильтров, заданных при их добавлении в базу. Это плохое решение, регулярно приводящее к проблемам. Но если для каждой функции будет автоматически выведена информация о ее характеристиках (сложность, требования к ресурсам, зависимости...), то можно будет задавать разные требования к программе и будут выбираться разные пути в графе.
Т.е. работа разработчика ПО сведется к составлению правильной спецификации. Нужно будет лишь правильно описать тип функции и требования к ее свойствам, составление же ее тела будет осуществляться автоматически, как сегодня автоматически зажигаются фонари.
Сохранено
|
|
</> |
Оставить комментарий
Популярные посты:
Архив записей в блогах:
Залежались у меня на кухне бооольшие и пузатые кабачки. Они-то мне и нужны))) Как же блюдо назвать? К примеру, "кольца кабачков с фаршем"! Пойдет? 2. Нарезаем кабачок кольцами и обжариваем на сковороде. Думаю, с одной стороны на растительном масле будет достаточно 2. Мясной фарш ...
ну чё, куснули хуйцу со своим Растеряевым ? больше не "цепляет"? :-) а мэшап Арабесок с Нирваной ШИКАРНЫЙ - звучит ужасно, но зато тащит как зараза. вот это таки-да реальная русская музыка, ...
7 июля 1881 года в своем первом номере еженедельный флорентийский "Журнал для детей" начал публикацию повести-сказки Карло Коллоди "История одного бураттино по имени Пиноккио".
...
Эта тактика рассчитана для тех кто не стесняться воровать у друзей исчитает это обычным делом! за 7 дней мы попробуем взять 14-ый уровень! Первое что вы должны для себя усвоить, такэто то что вам часто придётся выполнять это требование:Активно ...
