 Выбор между ванной и душевой кабиной
Выбор между ванной и душевой кабиной  Когда власть продвигает репродуктивную барщину - новорожденные падают в
Когда власть продвигает репродуктивную барщину - новорожденные падают в  Вечер вопросов и ответов
Вечер вопросов и ответов  Вопрос.
Вопрос.  31 марта ● Международный день резервного копирования (День бэкапа)...
31 марта ● Международный день резервного копирования (День бэкапа)...  Читающая Британия
Читающая Британия  Фильм "Хронос" - русская фантастика с душой. 2022 г.
Фильм "Хронос" - русская фантастика с душой. 2022 г.  Иностранное оружие киевских милиционеров.
Иностранное оружие киевских милиционеров.  В свете равноденствия
В свете равноденствия
28.07.2010 —
Алкоголь и профессия
Практичные регулярки: современные движки рвут и мечут
 lionet — 31.07.2010
Как известно, секрет правильного приготовления движков по
выполнению регулярных выражений был когда-то промышленностью
изобретён (grep, awk), утерян (Perl, Python, PHP, Ruby), и
изобретён вновь.
lionet — 31.07.2010
Как известно, секрет правильного приготовления движков по
выполнению регулярных выражений был когда-то промышленностью
изобретён (grep, awk), утерян (Perl, Python, PHP, Ruby), и
изобретён вновь.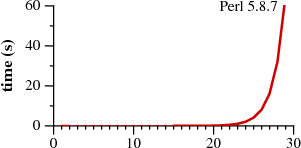 |
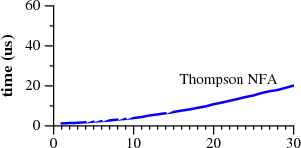 |
Время сопоставления
an с образцом
a?nan. |
|
Проект Google Re2 (C++) — успешная попытка [вос]создать промышленный regex движок, свободный от экспоненциальной зависимости от входных данных. Этот проект, выполненный Рассом Коксом (Russ Cox), дал возможность гуглу эффективно выполнять поиск по регулярным выражениям в программном коде, найденном гуглом в интернете. В качестве ценнейшего артефакта были порождены три статьи про построение движков регулярок, давая интересный исторический контекст и описание эффективной имплементации.
- Regular Expression
Matching Can Be Simple And Fast (but is slow in Java, Perl, PHP,
Python, Ruby, ...) (Январь 2007)
В наши дни регулярные выражения стали блестящим примером того, как игнорирование хорошей теории порождает плохие программы. Имплементации регулярных выражений, использующиеся в современных популярных инструментах, значительно медленнее, чем те, которые использовались во многих Unix-программах тридцатилетней давности.
Эта статья описывает хорошую, годную теорию: регулярные выражения, конечные автоматы, и алгоритм поиска по регулярным выражениям, изобретённый Кеном Томпсоном в середине 1960-х. Эта статья также превращает теорию в практику, описывая простую реализацию томпсоновского алгоритма. Работа именно этой имплементации, занимающей менее 400 строк на C, показана на картинках сверху. Она работает быстрее, чем более сложные настоящие имплементации, использующиеся в Perl, Python, PCRE и др. Статья завершается дискуссией о том, как теория может быть реализована на практике в промышленных применениях.
http://swtch.com/~rsc/regexp/regexp1.html
Regular Expression Matching: the Virtual Machine Approach (Декабрь 2009)Предыдущая статья в этой серии описывает две главных стратегии по имплементированию движков регулярных выражений: в-худшем-случае-линейные стратегии, базирующиеся на NFA и DFA, которые используются в awk, egrep и в большинстве современных grep'ов, и в-худшем-случае-экспоненциальная стратегия с откатами, которая используется практически во всех остальных движках, включая ed, sed, Perl, PCRE и Python.
Эта статья представляет две стратегии как два разных способа имплементации виртуальной машины, которая выполняет регулярное выражение, представленное в виде текстораспознающих байткодов. Примерно так, как .NET и Mono — разные способы исплементации виртуальной машины, которая выполняет коды программы скомпилированной в байткоды CLI.
http://swtch.com/~rsc/regexp/regexp2.html
Regular Expression Matching: the Virtual Machine Approach (Март 2010)В предыдущих двух статьях этой серии были описаны основы того, как писать движки регулярных выражений на DFA и NFA. Обе статьи основывались на игрушечных имплементациях, оптимизированных под то, чтобы объяснить базовые идеи. Эта статья основывается на рабочей имплементации.
Я провёл лето 2006 года делая Code Search, позволяющий программистам искать исходный код по регулярным выражениям. То есть, позволяет грепать по мировому публично доступному программному коду. Для поиска с использованием регулярных выражений мы сначала хотели использовать PCRE, пока мы не поняли, что он использует алгоритм с откатами, легко позволяя делать поиск за экспоненциальное время или с использованием произвольного размера стека. Так как Code Search выполняет произвольные регулярные выражения, приходящие из сети, использование PCRE означало бы открыть сервис для DoS атак. В качестве альтернативы PCRE, я написал новый, тщательно отрецензированный парсер регулярных выражений, в который была завёрнута свободная имплементация grep от Кена Томпсона, использующая быстрый DFA.
В течение следующих трёх лет я реализовал несколько новых бэк-ендов, которые в сумме заменили grep и расширили функциональность за пределы того, что требуется от POSIX grep. Результат, RE2, обеспечивает большинство функциональности PCRE используя C++ интерфейс, очень похожий на PCRE, но гарантируя выполнение за линейное время и фиксированный размер стека. RE2 широко распространён в Google, как Code Search так и во внутренних системах типа Sawzall или Bigtable.
Over the next three years, I implemented a handful of new back ends that collectively replaced the grep code and expanded the functionality beyond what is needed for a POSIX grep. The result, RE2, provides most of the functionality of PCRE using a C++ interface very close to PCRE's, but it guarantees linear time execution and a fixed stack footprint. RE2 is now in widespread use at Google, both in Code Search and in internal systems like Sawzall and Bigtable.
По состоянию на март 2010, RE2 является проектом с открытым кодом, с открытой для общественности разработкой. Эта статья — тур по исходникам RE2, показывающий, как методы из первых двух статей применяются в промышленной имплементации.
http://swtch.com/~rsc/regexp/regexp3.html - Да и вообще, Implementing Regular
Expressions
http://swtch.com/~rsc/regexp/
В сентябре 2010 мир пополнится ещё одним таким must-read ресурсом по регулярным выражениям. Пьеса (!) A Play on Regular Expressions (http://sebfisch.github.com/haskell-regexp/regexp-play.pdf) (via
Алгоритм, и соответствующая ему имплементация, Weighted RegExp Matching на простых выражениях обычно медленнее, чем другие библиотеки типа pcre, но у неё асимптотически лучшее поведение: O(nm) от длины входных данных и размера выражения. Пользуясь ленивостью, на некоторых бенчмарках (
.*a.{20}a.*) эта Haskell-имплементация обгоняет Re2,
описанный выше, по абсолютному времени выполнения.Weighted-regexp для Haskell доступна на Hackage: http://hackage.haskell.org/package/weighted-regexp
Также алгоритм, описанный в «A Play on Regular Expressions», был имплементирован на Python всего в нескольких десятках строках кода:
-
An Efficient and Elegant Regular Expression Matcher in Python
(Май 2010)
Две недели назад я принял участие в Workshop Programmiersprachen und Rechenkonzepte, ежегодном собрании немецких исследователей в области языков программирования. На семинаре Frank Huch и Sebastian Fischer дали замечательную лекцию по элегантному матчеру регулярных выражений, написанному на Haskell. Одной из целей дизайна матчера было линейное время выполнения в зависимости от входной строки (т. е., отсутствие возвратов) и линейноя зависимость от регулярного выражения. Использование памяти тоже должно было быть линейно-зависимым от размера регулярного выражения.
Во время семинара мы с несколькими Haskell-программистами реализовали этот алгоритм на (R)Python. Участвовали Frank, Sebastian, Baltasar Tranc?n y Widemann, Bernd Bra?el и Fabian Reck.
В этой статье я хочу описать эту имплементацию и покажу код, потому что он очень прост. В следующей статье я покажу, какие оптимизации можно задействовать в PyPy над этим матчером, и сделаю сравнения производительности.
http://morepypy.blogspot.com/2010/05/efficient-and-elegant-regular.html -
A JIT for Regular Expression Matching (Июнь 2010)
В этой статье я хочу показать, как JIT генератор из проекта PyPy может быть использован для превращения элегантного, но недостаточно быстрого матчера регулярных выражений, описанного в предыдущей статье, в достаточно быструю имплементацию. В дополнении к этому, я покажу некоторые измерения производительности в сравнении с различными другими имплементациями регулярных выражений.
http://morepypy.blogspot.com/2010/06/jit-for-regular-expression-matching.html
Самое интересное, что тот же алгоритм был написан ещё и на C++ и Java, и на Java получился в два раза быстрее, несмотря на то, что алгоритм очень хорошо ложится на ОО, и может быть переносим между ОО-языками без особых изменений:
To get a feeling for the orders of magnitude involved, the CPython re module (which is implemented in C and quite optimized) can match 2'500'000 chars/s. Google's new re2 implementation still matches 550'000 chars/s. Google's implementation is slower, but their algorithm gives complexity and space guarantees similar to our implementation in the last blog post.
[…]
The C++ version is a little bit faster than the RPython version translated to C, at 750'000 chars/s. That's not very surprising, given their similarity. The Java version is more than twice as fast, with 1'920'000 chars/s. Apparently the Java JIT compiler is a lot better at optimizing the method calls in the algorithm or does some other optimizations.
[…]
With the regular expression matcher translated to C and with a generated JIT, the regular expression performance increases significantly. Our running example can match 16'500'000 chars/s, which is more than six times faster than the re module. This is not an entirely fair comparison, because the re module can give more information than just "matches" or "doesn't match", but it's still interesting to see. A more relevant comparison is that between the program with and without a JIT: Generating a JIT speeds the matcher up by more than 20 times.
Implementation язык (ред. — lionet)
chars/s speedup over pure Python Pure Python code Python 12'200 1 Python re module C 2'500'000 205 Google's re2 implementation C++ 550'000 45 RPython implementation translated to C Python 720'000 59 C++ implementation C++ 750'000 61 Java implementation Java 1'920'000 157 RPython implementation with JIT Python 16'500'000 1352
Это, в частности, подтверждает тезис о том, что C++ не нужен: современные языки с GC и JIT просто уделывают его на традиционных для C/C++ задачах.
Оставить комментарий
Популярные посты:
Предыдущие записи блогера :
26.07.2010 —
Echo и Коровий Кликер
Архив записей в блогах:
Под катом рецептики шоколадного, медово-цирусового, ванильного и конфетного (?) блесков для губ Шоколадный блеск для губ - 4-5 штучек шоколадной стружки - 3 полные столовые ложки масло-какао - 1 капсула витамина Е Растапливаем все это, хорошо перемешивая ложкой, затем наливаем в ...
Ищу квартиру клиенту: кондоминиум, район Upper West Side, с одной или с двумя спальнями, бюджет до $1.2млн. Поскольку бюджет ограниченный, то смотрим в основном выше улицы West 72 street. Район от улицы West 59 до улицы West 72 не рассматриваем, поскольку цены там неподъемные. Но именно ...
Уж очень она мне нравится :-)
...
Одна из самых больших и старейших в России коллекций обитателей засушливых мест нашей планеты, более 2 тысяч видов и форм. До такой степени разных, что захотелось показать их отдельно. Поэтому дальше текста не будет вовсе, только фото. Смотрим?
...
Во Владивостоке "расхитители гробниц" в погонах планомерно уничтожают памятник федерального значения! И сейчас под прикрытием "отцов-командиров" и "наличия на форту" воинской части, уголовники в погонах безнаказанно в своё удовольствие распиливают металлические части, которые до них ...



